
The future is already here – it’s just not evenly distributed
William Gibson
Warum ein Buch über künstliche Intelligenz in einem Blog über Lernen?
Neben einer guten Medienkompetenz sollte heute jeder auch eine KI-Kompetenz besitzen. Diesen Aufruf von Philip Häusser im Buch Natürlich alles künstlich kann ich nur unterstreichen. Einschätzen zu können, was durch künstliche Intelligenz (KI) alles möglich ist oder was noch nicht möglich ist wird immer wichtiger.
Im Kontext Lernen gibt es bereits erste interessante Ansätze. So gibt es KI basierte adaptive Lernprogramme, die Lernpfade individuell und in Echtzeit an die Bedürfnisse der Lerner anpassen. Ein weiteres Beispiel sind Learning Experience Systeme (LXP) die Lerninhalte aggregieren und basierend auf meinen persönlichen Präferenzen weitere Lernangebote vorschlagen. Auch wenn ich den Eindruck habe, dass wir hier noch in den Kinderschuhen stecken, gibt es viel Potential. Bedenkt man, dass es in digitalen Bereichen meist exponentielles Wachstum gibt, können neue Lösungen schneller kommen als wir alle denken.
Zusätzlich gibt es in fast jedem Bereich mit denen Learning Professionals zusammenarbeiten Veränderungen durch Automatisierung, Machine Learning und künstlicher Intelligenz. Umso wichtiger also für Learning Professionals sich mit dem Thema Machine Learning zu beschäftigen. Denn, wie Karlheinz Pape in seinem Artikel „Wer in die Zukunft führen will, muss schon mal da gewesen sein“ schreibt, „Kennen wir das von den Mitarbeitenden künftig zu betretende Gelände?„. Wir müssen das Gelende kennen um als „Bergführer“ andere auf ihrem Weg begleiten zu können.
Eine aus meiner Sicht gute Möglichkeit um sich mit den Möglichkeiten, Hintergründen, Herausforderungen und Grenzen von künstlicher Intelligenz vertraut zu machen stellt das Buch „Natürlich alles künstlich: was künstliche Intelligenz kann und was (noch) nicht – KI erklärt für alle“ von Philip Häusser dar.
In diesem Artikel möchte ich einige Aspekte, die ich aus dem Buch gelernt habe, reflektieren und teilen.
Review: Natürlich alles künstlich
Das Buch in aller Kürze
In einfacher Art und Weise vermittelt das Buch was mit KI heute alles möglich ist, welche Typen von Machine Learning es gibt und wie diese grob funktionieren. Dabei wird auch immer auf die Einschränkungen der bestehenden Modelle und die Risiken wie z.B. das intensive Nutzen von Korrelationen hingewiesen. Philip Häusser findet eine sehr gute Mischung aus sehr einfach dargestellter Theorie und gut nachvollziehbaren Beispielen oder Analogien. Tieferes technisches Verständnis oder Statistikkenntnisse sind aus meiner Sicht nicht notwendig.
Wer sich intensiver mit dem Thema AI im Kontext Lernen beschäftigen möchte kann vielleicht lieber zu dem Buch Artificial Intelligence for Learning, Donald Clark greifen (welches ich selbst noch nicht gelesen habe). Natürlich alles künstlich kann aber sicher eine gute Wissensbasis für die weitere Arbeit in dem Bereich legen.
Empfehlen kann ich das kurzweilige gesprochene Hörbuch, welches von Philip Häusser selbst gelesen wird.
Was ich aus dem Buch mitgenommen habe
Was ist eigentlich ein Algorithmus?
Das Buch nutzt eine einprägsame Analogie:
Einen Algorithmus kann man sich vorstellen wie ein Kochrezept.
- Der Algorithmus benötigt Daten als Input, das wären beim Kochrezept die Zutaten.
- Anschließend gibt es eine Verarbeitung. Dies entspricht der Kochanleitung: in welcher Reihenfolge sollen welche Zutaten wie hinzugefügt werden und wie lange wird bei welcher Temperatur gekocht?
- Am Ende gibt es einen Output, beim Kochen entsteht eine Speise.
Eine künstliche Intelligenz arbeitet nach dem gleichen Prinzip. Der Unterschied ist, dass die Datenmenge extrem viel größer und der Verarbeitungsprozess um ein Vielfaches komplexer ist.
Arten von KI
Generell können zwei verschiedene Typen künstlicher Intelligenz unterscheiden werden: die Artificial Narrow Intelligence (ANI) und die Artificial General Intelligence (AGI).
Bisher gibt es lediglich Systeme im Bereich der Artificial Narrow Intelligence. Dabei handelt es sich um Systeme, die auf spezielle Bereiche trainiert und optimiert sind. Dort können sie auch gute Leistungen erzielen. Diese Systeme brauchen immer sehr erfahrene Entwickler bzw. Data Scientists, um die Algorithmen auf das jeweilige Problem zu optimieren.
Eine Artificial General Intelligence oder auch „Starke KI“ gibt es bisher nicht. Es gibt auch noch keine Idee wie diese Entwickelt werden könnte. Solch eine starke KI würde selbständig in beliebigen Feldern lernen können.
Im Bereich der Artificial Narrow Intelligence (ANI) gibt es ebenfalls verschiedene Ansätze, die im Buch näher erläutert werden. Ein Begriff, den man häufig hört, ist Deep Learning. Beim Deep Learning werden künstliche neuronale Netze verwendet. Ein einzelnes künstliches Neuron scheint erstmal nicht sehr komplex zu sein. Diese Neuronen können trainiert werden und dadurch Verbindungen zu anderen Neuronen aufbauen und Gewichtungen dieser Verbindungen anpassen. Hat man ein entsprechend tiefes neuronales Netzwerk erstellt können diese mit genügend Daten trainiert werden, um Korrelationen in Daten zu erkennen.
Warum künstliche Intelligenzen große Datenmengen benötigen?

Anders als wir Menschen, die bereits aus sehr geringen Datenmengen Modelle ableiten können, brauchen KIs sehr große Datenmengen. Man kann sich wie in dem oben dargestellten Streupunktediagramm vorstellen. Das System versucht zusammenhängende Cluster zu erkennen. Dabei haben die Daten meist eine Vielzahl von Dimensionen und nicht nur zwei, wie in der oben gewählten Darstellung. In der Regel sind die Daten auch nicht so trennscharf. Dadurch ergibt sich der Bedarf an sehr großen Datenmengen, um die neuronalen Netzwerke von KIs trainieren zu können und genügend Korrelationen für Cluster erkennen zu können.
Um KIs zu trainieren nutzt man sogenannte Trainingsdatensätze. Wurde die KI mit diesen Trainingsdatensatz trainiert, wird sie anschließend mit abweichenden Datensätzen, den Test und Validierungsdatensatz geprüft. Dies geschieht, um die Qualität der Analysen zu messen und um zu vermeiden, dass die KI nur mit den Trainingsdatensatz gute Ergebnisse erzielt. Zusätzlich versucht man so das Problem zu vermeiden, dass der Algorithmus überoptimiert wird (das sogenannte Overfitting).
Reinforcement Learning: Wie lernt ein Algorithmus Schach oder Go Spielen?
Wie oben erwähnt: Eine KI funktioniert immer dann gut, wenn sehr viele Daten für das Training verfügbar sind. Möchte man einer KI Schach beibringen, so gibt es verschiedene Lösungen:
- Es viele dokumentierte Schachpartien, die man nutzen kann, um eine KI zu trainieren. Dadurch kenn das System bereits die meisten der häufig vorkommenden Züge und wird somit ein sehr starker Gegner.
- Eine darüber hinaus gehende Variante stellt das Reinforcement Learning dar. Dabei lernt das System in Anlehnung an natürliches Lernen: durch Belohnungen, der klassischen Konditionierung. Positives verhalten (z.B. ein Schachzug der gut ist und die Siegwahrscheinlichkeit erhöht) wird belohnt. Dadurch kann das System selbständig lernen welche Schachzüge besser sind als andere und durch jede Partie, die gegen das System gespielt wird, wird das System stärker. Man müsste es nur häufig genug gegen verschiedene Meister spielen lassen
- Noch schneller können aber weitere Trainingsdaten erzeugt werden, indem man einfach zwei Schach-KIs gegeneinander spielen lässt. So können die beiden Systeme in kürzester Zeit Millionen Schachpartien gegeneinander spielen und so quasi unschlagbar werden.
Ein Beispiel, welches nach der dritten Variante trainiert wurde, war die Go-KI „Alpha Go Zero“. Der größte Trick dabei war, bei jedem Zug berechnen zu können, ob der Zug die Gewinnwahrscheinlichkeit erhöhte. Dabei liegt auch die Schwierigkeit in realen Szenarien.
Meist haben wir keine so klaren Regeln wie beim Schach und Go. Würde man es auf das Autofahren übertragen, könnte ein System z.B. beobachten, wie Millionen Autofahrer in verschiedenen Situationen reagieren und davon lernen. Doch das System wüsste nie, ob die Entscheidung des Autofahrers die beste Entscheidung oder vielleicht eine falsche Entscheidung war. Vielleicht würde die KI an einer bestimmten Stelle basierend auf den Trainingsdaten anders entscheiden, doch wäre diese Entscheidung besser?
Beispiele was bereits mit KIs möglich ist
Bildmanipulation mit GANs

Besonders eindrucksvoll erschienen mir die Beispiele, die mit GANs (Generative Adversarial Networks) möglich sind. So kann man zum Beispiel einem GAN zwei verschiedenen Bilder als Daten zur Verfügung stellen. Dabei definiert ein Bild den Stil und das zweite Bild den Inhalt. Das GAN erzeugt dann als Beispiel aus einem realen Bild einfach ein Bild in einer bestimmten Kunstrichtung wie die Abbildung oben zeigt. Solch ein System kann aber auch aus einem Pferd ein Zebra erzeugen, wie man in dem Video Turning a horse video into a zebra video sehen kann. Noch ist das Zebra gut als Fake zu erkennen, aber das ist vermutlich nur eine Frage der Zeit. Mit solchen Techniken ist es auch möglich in Videos z.B. Gesichter auszutauschen.
Hier zwei Sites, die das Überlagern von Stil und Inhalt zweier Bilder Ermöglichen:
- Fotor’s NFT Creator – GoArt, Turns Your Digital Photos into NFT Artworks
- AI Generated Art Prints – NightCafe Creator
Wer weitere Beispiele sehen möchte, was GANs alles erzeugen können, kann sich die Seite 18 Impressive Applications of Generative Adversarial Networks (GANs) ansehen.
Deepfake: AI generierte Gesichter

Mittlerweile können auch einfach sehr realitätsnahe Bilder von Menschen durch KIs erzeugt werden. Das Bild oben zeigt drei Fotos die ich mit wenigen Klicks Aufwand mit dem Tool Face Generator (generated.photos) erzeugt habe. Manche Ergebnisse sehen noch unrealistisch aus aber die meisten sind doch erschreckend realistisch.
In einer Studie wurde festgestellt, dass es uns sehr schwer fällt künstlich erstellte Gesichter zu erkennen wie z.B. in diesem Artikel nachgelsen werden kann: People Trust Deepfake Faces Generated by AI More Than Real Ones, Study Finds.
Texterzeugung mit GPT-3
Ein weiteres aktuelles und eindrucksvolles Beispiel für KIs ist GPT-3 (Generative Pre-trained Transformer). Bei GPT-3 handelt es sich um ein vortrainiertes Modell, mit dem Texte erzeugt werden können. Vortrainiert bedeutet in diesem Zusammenhang, dass es mit Milliarden Textinformationen trainiert wurde. Mit GPT-3 ist es zum Beispiel möglich, mit wenigen Informationen, komplette Texte erzeugen oder verändern zu lassen. Die generierten Texte sind dabei von einer sehr hohen Qualität.
Es gab kurz nachdem GPT-3 verfügbar war bereits ein erstes Blog, das komplett mit GPT-3 erstellt worden ist und deswegen auch durch die Presse ging (siehe z.B. A college kid created a fake, AI-generated blog. It reached #1 on Hacker News.).
Der erste AI generierte Blogpost lautete:
Feeling unproductive? Maybe you should stop overthinking.
GPT-3
In order to get something done, maybe we need to think less. Seems counter-intuitive, but I believe sometimes our thoughts can get in the way of the creative process. We can work better at times when we „tune out“ the external world and focus on what’s in front of us.
I’ve been thinking about this lately, so I thought it would be good to write an article about it.
So what exactly does this mean? Well, for starters, let’s start with some definitions.
…
Quelle: Feeling unproductive? Maybe you should stop overthinking.
Anfälligkeit und Risiken von KIs
KIs durch Rauschen bewusst in die Irre führen

Die verschiedenen Ebenen der neuronalen Netze, die KIs nutzen, reagieren auf Daten immer mit einer gewissen Gewichtung. Kennt man den Trainingssatz der KI kann man analysieren, welche Pixel wie stark verändert werden müssen, um einen etwas andere Gewichtung zu erreichen. So kann teilweise minimales Rauschen in einem Bild dazu führen, dass es komplett falsch von einer KI kategorisiert wird. Ohne das zusätzliche Rauschen hätte die KI das Bild korrekt erkannt.
Sticker nutzen, die KIs besonders triggern: Adversarial Patches
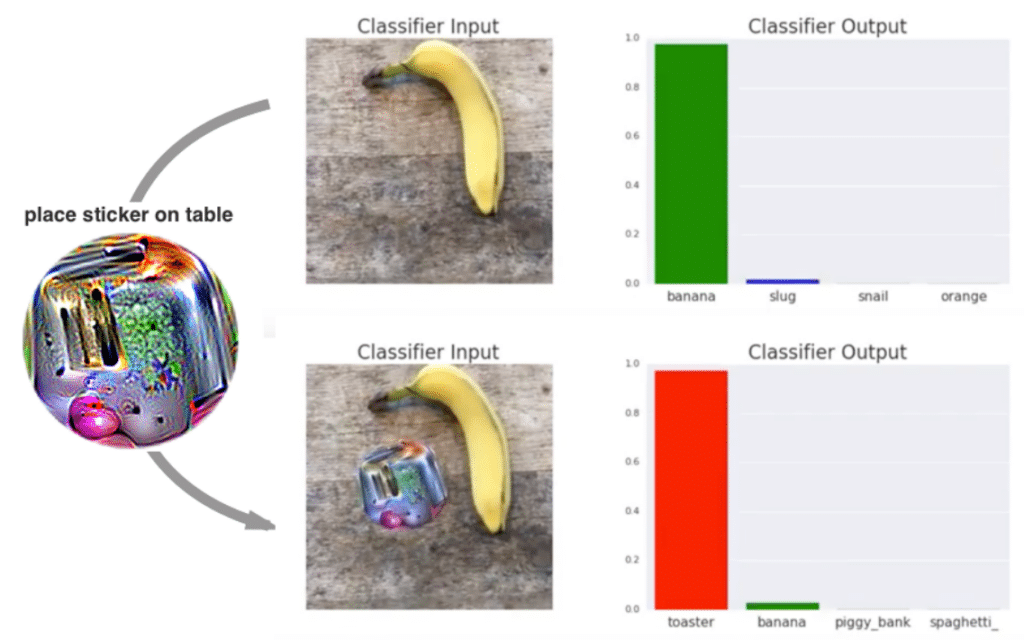
Eine weitere Möglichkeit sind sogenannte adversarial Patches. Dies sind Bilder, die eine Bilderkennungs-KI so stark triggern, dass diese nicht mehr das abgebildete Objekt erkennen, sondern z.B. einen Toaster. Für uns ist dabei auf diesem Patch nicht mal ein Toaster zu erkennen. KIs reagieren aber sehr stark auf Kanten und hohe Kontraste und das Bild wurde so angepasst, dass es die Erkennung einiger KIs beeinträchtigt.
Weitere Beispiele wie Angriffe auf KIs aussehen können findet man zum Beispiel hier:
Breaking neural networks with adversarial attacks
Manchmal braucht es vielleicht auch starre Regeln
Wenn mir Netflix oder Spotify etwas vorschlägt, was meinen Interessen nicht entspricht, ist das meist nicht schlimm, vielleicht lustig und höchsten ärgerlich. Wie ist es aber bei Situationen und in Rahmenbedingungen, die solche Fehler nicht erlauben?
Beispiel: Ein Auto steht an der Ampel bei Rot. Vielleicht hat die KI die Beobachtung gemacht, dass manche Autofahrer unter bestimmten Bedingungen doch bei Rot über die Ampel fahren. Vielleicht mitten in der Nacht auf einer unbefahrenen und gut einsehbaren Landstraße. Lernt die KI dann, dass man nachts bei leeren Straßen über Rot fahren darf? Vermutlich nicht, da dies in Trainingsdatensätze eine Ausnahme darstellen dürfte. Aber wir wissen meist nicht, ob es vielleicht doch eine besondere Konstellation der Daten gibt in der die KI anders entscheiden würde, wenn selbst leichtes (aber genau geplantes) Bildrauschen dazu führen kann, dass ein Bild durch eine KI komplett anders wahrgenommen werden kann.
Die Vorhersagemodelle werden niemals vollständig sein
Ein weiteres Beispiel aus dem Buch:
Ich kaufe mir mittags eine Kinokarte für einen Film am Abend. Wie hoch ist die Wahrscheinlichkeit, basierend auf der Datenlage, dass ich mir den Film anschauen werde?
Die Vorhersage ist vermutlich ziemlich eindeutig. Es kann aber immer Sonderfälle geben, die nicht in den Datenmodellen vorgesehen sind und nicht in den Trainingsdaten vorkamen. Wenn ich mir nach dem Kartenkauf zum Beispiel das Bein breche, wird jeder Mensch direkt verstehen, dass ich nicht ins Kino gehen werde. Einer normal trainierten KI wäre dieser Zusammenhang jedoch nicht klar und sie würde so zu einem falschen Schluss kommen. Diese und Situationen zweigen, dass der gesunde Menschenverstand nicht einfach durch eine KI abbildbar ist.
Risiko: Nutzung von Korrelationen

- Erhöht Radfahren das Risiko an Hautkrebs zu erkranken?
- Erhöhen weiße Oberteile die Wahrscheinlichkeit zu sterben?
- Führt die Veröffentlichung von Nickolas Cage Filmen dazu, dass mehr Menschen in Pools ertrinken?
Zu all diesen Fragen könnten Daten erhoben werden und es könnte sich herausstellen, dass es dazu klare Korrelationen gibt:
- Menschen, die viel Radfahren sind mehr an der Sonne und die vermehrte Sonneneinstrahlung kann das Hautkrebsrisiko erhöhen. Das erhöhte Risiko liegt aber nicht am Radfahren selbst.
- Menschen, die im Krankenhaus liegen tragen weiße Krankenhaushemden. Und im Krankenhaus ist das Risiko vermutlich größer, dass man stirbt. Man ist ja bereits krank. Aber mit dem weißen Krankenhaushemd hängt es nicht zusammen
- Den letzten Punkt muss ich vermutlich nicht weiter kommentieren. Eine von vielen nicht kausalen Korrelationen auf der Seite Spurious Correlccations.
All dies sind reine Korrelationen, die aus Daten abgeleitet werden könnten. Sie ergeben jedoch keinen Sinn und beschreiben nicht wirkliche kausale Zusammenhänge. Leider können KIs keinen Sinn und keine Kausalitäten erkennen, sondern nur Korrelationen. Daher ist es wichtig darauf zu achten, dass Empfehlungen von KIs nicht immer blind vertraut wird und dass Modelle möglichst auch erklärbar werden.
Philip Häusser erläutert ein Beispiel, bei dem er eine Erkennung für Baustellen entwickeln sollte. Eine erste Version lieferte auch sehr gute Erkennungsraten. Die KI nahm aber den Weg des geringsten Wiederstandes und erkannte nur die gelben Begrenzungsstreifen auf der Straße, welche in vielen Baustellen vorkommen. Da die gelben Begrenzungsstreifen aber nicht vorgeschrieben sind und in einigen Baustellen nicht vorkommen, ist diese Erkennung ungeeignet für ein autonom fahrendes Auto.
Fazit
Was ist noch echt und was ist Fake? Müssen wir zukünftig noch mehr Spam und Fake News erwarten, die einfach durch Maschinen erzeugt werden und immer realer wirken? Computererzeugte Fotos und Texte, die uns etwas glauben lassen, was nicht wahr ist? KIs können falsch und richtig nicht unterscheiden. Wenn sie mit fehlerhaften oder auch diskriminierenden Daten trainiert werden, werden die Modelle sich entsprechend verhalten.
Was wir alle tun sollten, ist eine KI-Kompetenz zu entwickeln. Diese wird neben der Medienkompetenz und dem kritischen Denken immer wichtiger werden. Gemeinsam werden uns diese drei Kompetenzen dabei helfen mit den weiteren zu erwarteten Entwicklungen mitgehen und umgehen zu können – auch im Lernkontext. Das Buch Natürlich alles künstlich kann dafür einen guten Start darstellen.
Links & Verwandte Podcasts
Mittlerweile ist mit ChatGPT Textgenerierung und interaktiver Dialog über eine sehr einfache Chatoberfläche möglich. Selbst als Podcast-Gast kann man ChatGPT einsetzen: ChatGPT als Podcast-Gast über New Learning (LernXP).
- Buch: Natürlich alles künstlich: Was künstliche Intelligenz kann und was (noch) nicht – KI erklärt für alle von Dr. Philip Häusser
- Wer mehr darüber erfahren möchte, wie Künstliche Intelligenz im Unternehmenskontext eingesetzt und eingeführt werden kann, dem kann ich den Coursera Kurs AI for Everyone von Andrew Ng empfehlen
Verpasse keine Updates – Jetzt abonnieren!
Hat dir der Beitrag gefallen?
Dann hol dir alle 4–8 Wochen das LernXP-Update mit frischen Impulsen, Trends und exklusiven Netzfunden direkt ins Postfach.
👉 Ja, ich will Lern-Impulse 🎓
2 Gedanken zu „Was kann künstliche Intelligenz und wo sind ihre Grenzen? Buchreview: Natürlich alles künstlich“